深入理解CPU的分支预测(Branch Prediction)模型
原文¶
背景¶
先来看一段 rust代码
use rand::{random, Rng};
fn sum(v: &Vec<i32>) -> i32 {
let t = std::time::Instant::now();
let mut count:i32 = 0;
for &i in v.iter(){
if i < 0{
count += i;
}
}
println!("{:?}", t.elapsed());
count
}
fn is_sorted(v: &mut Vec<i32>) -> i32 {
v.sort();
sum(v)
}
fn unsort(v: & Vec<i32>) -> i32 {
sum(v)
}
let mut rng = rand::thread_rng();
let mut v1 = Vec::with_capacity(100_0000);
let mut v2 = Vec::with_capacity(100_0000);
for _ in [(); 100_0000]{
let n:i8 = rng.gen();
v1.push(n as i32);
v2.push(n as i32);
}
let c = is_sorted(&mut v1);
println!("{:?}", c);
let c = unsort(&mut v2);
println!("{:?}", c);
211.453µs
-32201510
414.666µs
-32201510
再来看段c++代码,我们用256的模数随机填充一个固定大小的大数组,然后对数组的一半元素求和:
#include <algorithm>
#include <ctime>
#include <iostream>
int main()
{
// 随机产生整数,用分区函数填充,以避免出现分桶不均
const unsigned arraySize = 32768;
int data[arraySize];
for (unsigned c = 0; c < arraySize; ++c)
data[c] = std::rand() % 256;
// !!! 排序后下面的Loop运行将更快
std::sort(data, data + arraySize);
// 测试部分
clock_t start = clock();
long long sum = 0;
for (unsigned i = 0; i < 100000; ++i)
{
// 主要计算部分,选一半元素参与计算
for (unsigned c = 0; c < arraySize; ++c)
{
if (data[c] >= 128)
sum += data[c];
}
}
double elapsedTime = static_cast<double>(clock() - start) / CLOCKS_PER_SEC;
std::cout << elapsedTime << std::endl;
std::cout << "sum = " << sum << std::endl;
}
编译并运行:
在我的macbook air上运行结果:
# 1. 取消std::sort(data, data + arraySize);的注释,即先排序后计算
10.218
sum = 312426300000
# 2. 注释掉std::sort(data, data + arraySize);即不排序,直接计算
29.6809
sum = 312426300000
由此可见,先排序后计算,运行效率有进3倍的提高。
为保证结论的可靠性, 我们再用java来测一遍:
import java.util.Arrays;
import java.util.Random;
public class Main
{
public static void main(String[] args)
{
// Generate data
int arraySize = 32768;
int data[] = new int[arraySize];
Random rnd = new Random(0);
for (int c = 0; c < arraySize; ++c)
data[c] = rnd.nextInt() % 256;
// !!! With this, the next loop runs faster
Arrays.sort(data);
// Test
long start = System.nanoTime();
long sum = 0;
for (int i = 0; i < 100000; ++i)
{
// Primary loop
for (int c = 0; c < arraySize; ++c)
{
if (data[c] >= 128)
sum += data[c];
}
}
System.out.println((System.nanoTime() - start) / 1000000000.0);
System.out.println("sum = " + sum);
}
}
在intellij idea中运行结果:
也有三倍左右的差距。且java版要比c++版整体快近乎1倍?这应该是编译时用了默认选项,gcc优化不够的原因,后续再调查这个问题。
问题的提出¶
以上代码在数组填充时已经加入了分区函数,充分保证填充值的随机性,计算时也是按一半的元素来求和,所以不存在特例情况。而且,计算也完全不涉及到数据的有序性,即数组是否有序理论上对计算不会产生任何作用。在这样的前提下,为什么排序后的数组要比未排序数组运行快3倍以上?
分析¶
想象一个铁路分叉道口。

为了论证此问题,让我们回到19世纪,那个远距离无线通信还未普及的年代。你是铁路交叉口的扳道工。当听到火车快来了的时候,你无法猜测它应该朝哪个方向走。于是你叫停了火车,上前去问火车司机该朝哪个方向走,以便你能正确地切换铁轨。
要知道,火车是非常庞大的,切急速行驶时有巨大的惯性。为了完成上述停车-问询-切轨的一系列动作,火车需耗费大量时间减速,停车,重新开启。
既然上述过车非常耗时,那是否有更好的方法?当然有!当火车即将行驶过来前,你可以猜测火车该朝哪个方向走。
- 如果猜对了,它直接通过,继续前行。
- 如果猜错了,车头将停止,倒回去,你将铁轨扳至反方向,火车重新启动,驶过道口。
如果你不幸每次都猜错了,那么火车将耗费大量时间停车-倒回-重启。如果你很幸运,每次都猜对了呢?火车将从不停车,持续前行!
上述比喻可应用于处理器级别的分支跳转指令里:
原程序:
汇编码:
让我们回到文章开头的问题。现在假设你是处理器,当看到上述分支时,当你并不能决定该如何往下走,该如何做?只能暂停运行,等待之前的指令运行结束。然后才能继续沿着正确地路径往下走。
要知道,现代编译器是非常复杂的,运行时有着非常长的pipelines, 减速和热启动将耗费巨量的时间。
那么,有没有好的办法可以节省这些状态切换的时间呢?你可以猜测分支的下一步走向!
- 如果猜错了,处理器要flush掉pipelines, 回滚到之前的分支,然后重新热启动,选择另一条路径。
- 如果猜对了,处理器不需要暂停,继续往下执行。
如果每次都猜错了,处理器将耗费大量时间在停止-回滚-热启动这一周期性过程里。如果侥幸每次都猜对了,那么处理器将从不暂停,一直运行至结束。
上述过程就是分支预测(branch prediction)。虽然在现实的道口铁轨切换中,可以通过一个小旗子作为信号来判断火车的走向,但是处理器却无法像火车那样去预知分支的走向--除非最后一次指令运行完毕。
那么处理器该采用怎样的策略来用最小的次数来尽量猜对指令分支的下一步走向呢?答案就是分析历史运行记录: 如果火车过去90%的时间都是走左边的铁轨,本次轨道切换,你就可以猜测方向为左,反之,则为右。如果在某个方向上走过了3次,接下来你也可以猜测火车将继续在这个方向上运行...
换句话说,你试图通过历史记录,识别出一种隐含的模式并尝试在后续铁道切换的抉择中继续应用它。这和处理器的分支预测原理或多或少有点相似。
大多数应用都具有状态良好的(well-behaved)分支,所以现代化的分支预测器一般具有超过90%的命中率。但是面对无法预测的分支,且没有识别出可应用的的模式时,分支预测器就无用武之地了。
关于分支预测期,可参考维基百科相关词条"Branch predictor" article on Wikipedia..
文首导致非排序数组相加耗时显著增加的罪魁祸首便是if逻辑:
注意到data数组里的元素是按照0-255的值被均匀存储的(类似均匀的分桶)。数组data有序时,前面一半元素的迭代将不会进入if-statement, 超过一半时,元素迭代将全部进入if-statement.
这样的持续朝同一个方向切换的迭代对分支预测器来说是非常友好的,前半部分元素迭代完之后,后续迭代分支预测器对分支方向的切换预测将全部正确。
简单地分析一下:有序数组的分支预测流程:
T = 分支命中
N = 分支没有命中
data[] = 0, 1, 2, 3, 4, ... 126, 127, 128, 129, 130, ... 250, 251, 252, ...
branch = N N N N N ... N N T T T ... T T T ...
= NNNNNNNNNNNN ... NNNNNNNTTTTTTTTT ... TTTTTTTTTT (非常容易预测)
无序数组的分支预测流程:
data[] = 226, 185, 125, 158, 198, 144, 217, 79, 202, 118, 14, 150, 177, 182, 133, ...
branch = T, T, N, T, T, T, T, N, T, N, N, T, T, T, N ...
= TTNTTTTNTNNTTTN ... (完全随机--无法预测)
在本例中,由于data数组元素填充的特殊性,决定了分支预测器在未排序数组迭代过程中将有50%的错误命中率,因而执行完整个sum操作将会耗时更多。
优化¶
利用位运算取消分支跳转。基本知识:
|x| >> 31 = 0 # 非负数右移31为一定为0
~(|x| >> 31) = -1 # 0取反为-1
-|x| >> 31 = -1 # 负数右移31为一定为0xffff = -1
~(-|x| >> 31) = 0 # -1取反为0
-1 = 0xffff
-1 & x = x # 以-1为mask和任何数求与,值不变
故分支判断可优化为:
分析:
- data[c] < 128, 则statement 1值为: 0xffff = -1, statement 2等号右侧值为: 0 & data[c] == 0;
- data[c] >= 128, 则statement 1值为: 0, statement 2等号右侧值为: ~0 & data[c] == -1 & data[c] == 0xffff & data[c] == data[c];
故上述位运算实现的sum逻辑完全等价于if-statement, 更多的位运算hack操作请参见bithacks.
若想避免移位操作,可以使用如下方式:
结论¶
- 使用分支预测: 是否排序严重影响performance
- 使用bithack: 是否排序对performance无显著影响
这个例子告诉给我们启示: 在大规模循环逻辑中要尽量避免数据强依赖的分支(data-dependent branching).
补充知识¶
Pipeline¶
先简单说明一下CPU的instruction pipeline(指令流水线),以下简称pipeline。 Pipieline假设程序运行时有一连串指令要被运行,将程序运行划分成几个阶段,按照一定的顺序并行处理之,这样便能够加速指令的通过速度。
绝大多数pipeline都由时钟频率(clock)控制,在数字电路中,clock控制逻辑门电路(logical cicuit)和触发器(trigger), 当受到时钟频率触发时,触发器得到新的数值,并且逻辑门需要一段时间来解析出新的数值,而当受到下一个时钟频率触发时触发器又得到新的数值,以此类推。
而借由逻辑门分散成很多小区块,再让触发器链接这些小区块组,使逻辑门输出正确数值的时间延迟得以减少,这样一来就可以减少指令运行所需要的周期。 这对应Pipeline中的各个stages。
一般的pipeline有四个执行阶段(execuate stage): 读取指令(Fetch) -> 指令解码(Decode) -> 运行指令(Execute) -> 写回运行结果(Write-back).
分支预测器¶
分支预测器是一种数字电路,在分支指令执行前,猜测哪一个分支会被执行,能显著提高pipelines的性能。
条件分支通常有两路后续执行分支,not token时,跳过接下来的JMP指令,继续执行, token时,执行JMP指令,跳转到另一块程序内存去执行。
为了说明这个问题,我们先考虑如下问题。
没有分支预测器会怎样?¶
加入没有分支预测器,处理器会等待分支指令通过了pipeline的执行阶段(execuate stage)才能把下一条指令送入pipeline的fetch stage。
这会造成流水线停顿(stalled)或流水线冒泡(bubbling)或流水线打嗝(hiccup),即在流水线中生成一个没有实效的气泡, 如下图所示:
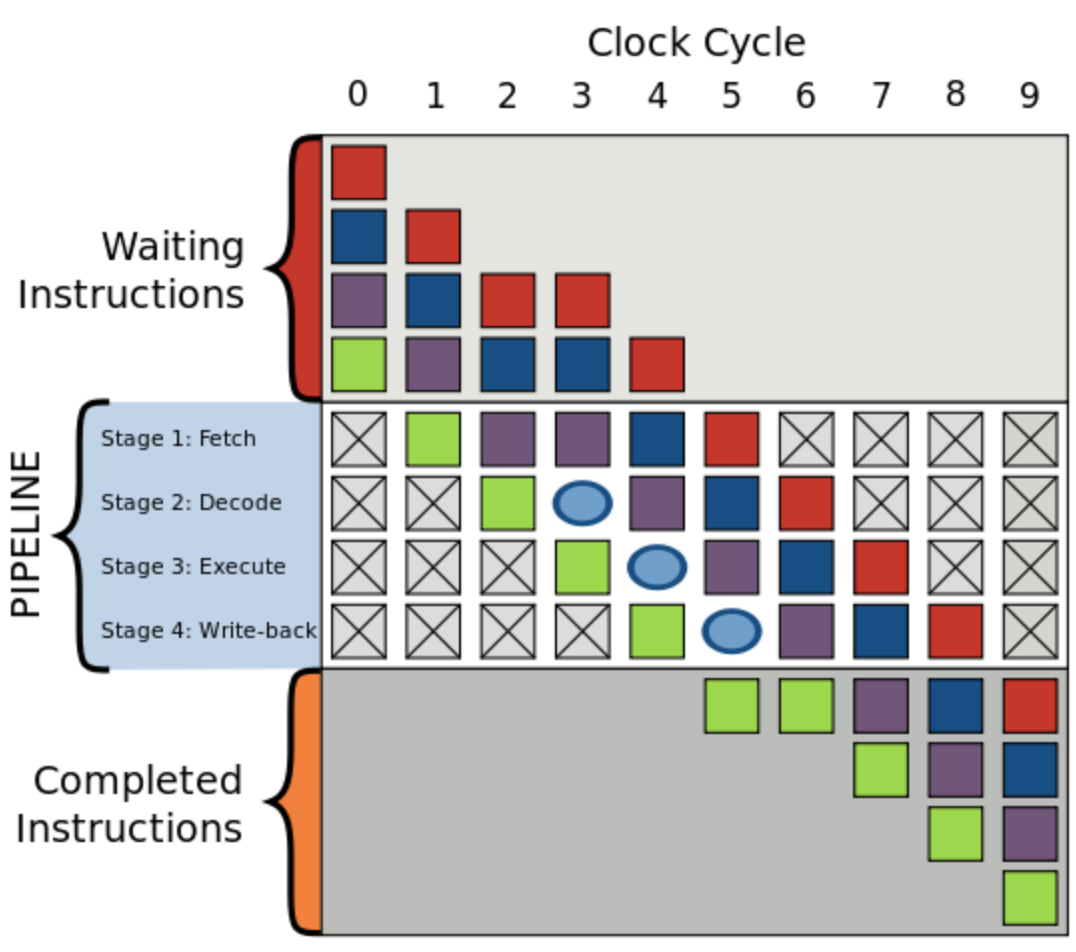
图中一个气泡在编号为3的始终频率中产生,指令运行被延迟。
Stream hiccup现象在早期的RISC体系结构处理器中常见。
有分支预测期的pipeline¶
我们来看分支预测器在条件分支跳转中的应用。条件分支通常有两路后续执行分支,not token时,跳过接下来的JMP指令,继续执行, token时,执行JMP指令,跳转到另一块程序内存去执行。
加入分支预测器后,为避免pipeline停顿(stream stalled),其会猜测两路分支哪一路最有可能执行,然后投机执行,如果猜错,则流水线中投机执行中间结果全部抛弃,重新获取正确分支路线上的指令执行。可见,错误的预测会导致程序执行的延迟。
由前面可知,Pipeline执行主要涉及Fetch, Decode, Execute, Write-back几个stages, 分支预测失败会浪费Write-back之前的流水线级数。现代CPU流水线级数非常长,分支预测失败可能会损失20个左右的时钟周期,因此对于复杂的流水线,好的分支预测器非常重要。
常见的分支预测器¶
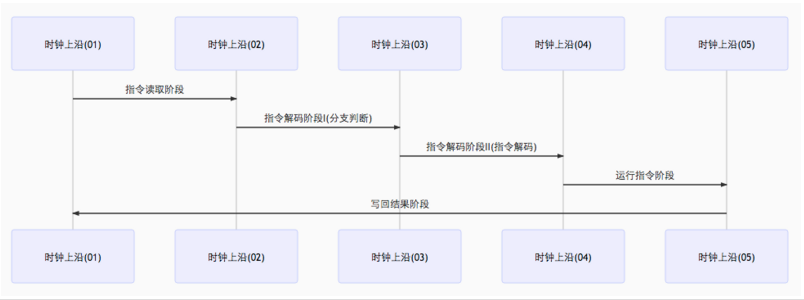
- 静态分支预测器
静态分支预测器有两个解码周期,分别评价分支,解码。即在分支指令执行前共经历三个时钟周期。详情见图:
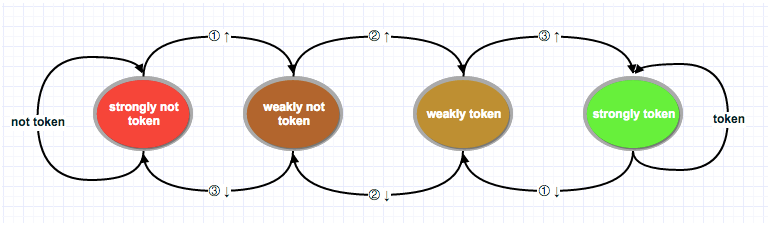
- 双模态预测器(bimodal predictor) 也叫饱和计数器,是一个四状态状态机. 四个状态对应两个选择: token, not token, 每个选择有两个状态区分强弱:strongly,weakly。分别是Strongly not taken,Weakly not taken, Weakly taken, Strongly taken。
状态机工作原理图如下:
 htt
htt
图左边两个状态为不采纳(not token),右边两个为采纳(token)。由not token到token中间有两个渐变状态。由红色到绿色翻转需要连续两次分支选择。
技术实现上可用两个二进制位来表示,00, 01, 10, 11分别对应strongly not token, weakly not token, weakly token, strongly token。 一个判断两个分支预测规则是否改变的简单方法便是判断这个二级制状态高位是否跳变。高位从0变为1, 强状态发生翻转,则下一个分支指令预测从not token变为token,反之亦然。
据评测,双模态预测器的正确率可达到93.5%。预测期一般在分支指令解码前起作用。
其它常见分支预测器如两级自适应预测器,局部/全局分支预测器,融合分支预测器,Agree预测期,神经分支预测器等。